![]()

The computational complexity of solving for global optimal control policies scales exponentially with the dimensionality of the state and input space of the underlying dynamical system. Policy Decomposition is a hierarchical control framework to lessen this curse of dimensionality. The framework automatically identifies suitable hierarchies to reduce the joint optimization of policies for all the control inputs to a system. Thereby policies for different inputs are derived either in a decoupled or in a cascaded fashion and only as functions of some subset of the state variables. Two examples hierarchies for a simple cartpole system with two control inputs are shown below.
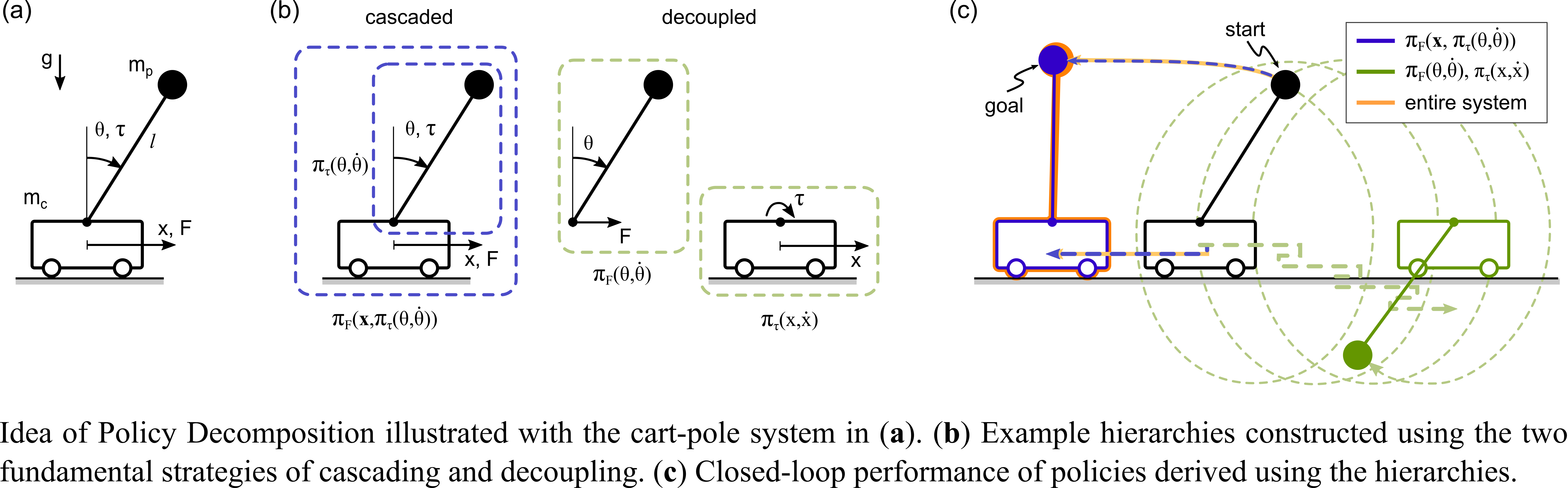
Generally, suitable hierarchies for control problems are either heuristically designed or are based on some open-loop measure. As a consequence, the resulting optimal control policies derived using such hierarchies can be highly suboptimal. In contrast, Policy Decomposition introduces a suboptimality metric to quantify the loss in closed-loop performance of hierarchical policies in comparison to the optimal policy. Furthermore, as this metric cannot be computed without solving for the policies, Policy Decomposition estimates it by solving relaxed versions of the policy optimization problem and thereby apriori assessing the suboptimality of different hierarchies. More details can be found in [1].

Several hierarchies can be constructed using a combination of the two fundamental strategies of cascading and decoupling shown above in the cartpole example. A general hierarchy can be uniquely represented using a tree-like structure. One example is shown below in Figure 2(a). The nodes of the tree consist of subsets of control inputs and state variables. Subtrees represent subsystems whose dynamics are described using state-variables in the entire subtree. Furthermore, these subsystems are controlled using the inputs situated at the root-node of the subtree. Subsystems that lie on different branches are decoupled for the sake of policy computation and those that lie on the same branch are in a cascade where policies to control the subsystems lower in the cascade are derived first. Figure 2(b) showcases a similar hierarchical structure identified by Policy Decomposition for the hover control of a quadcopter. In this hierarchy, the thrust and roll control is jointly optimized, lower in cascade to the pitch controller, and the yaw control is decoupled from the rest.

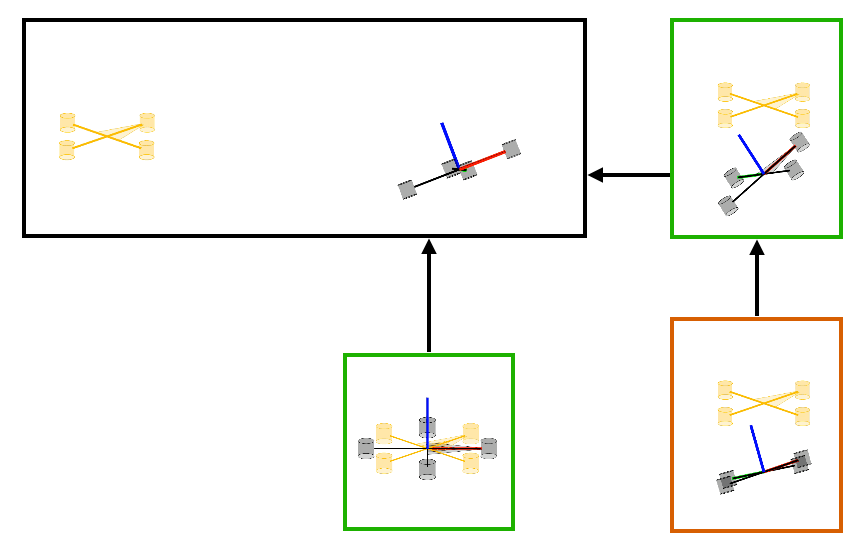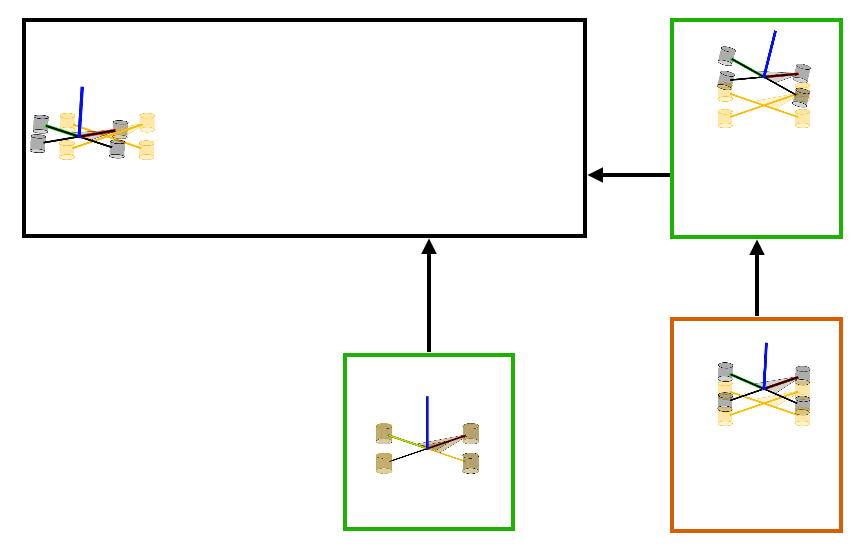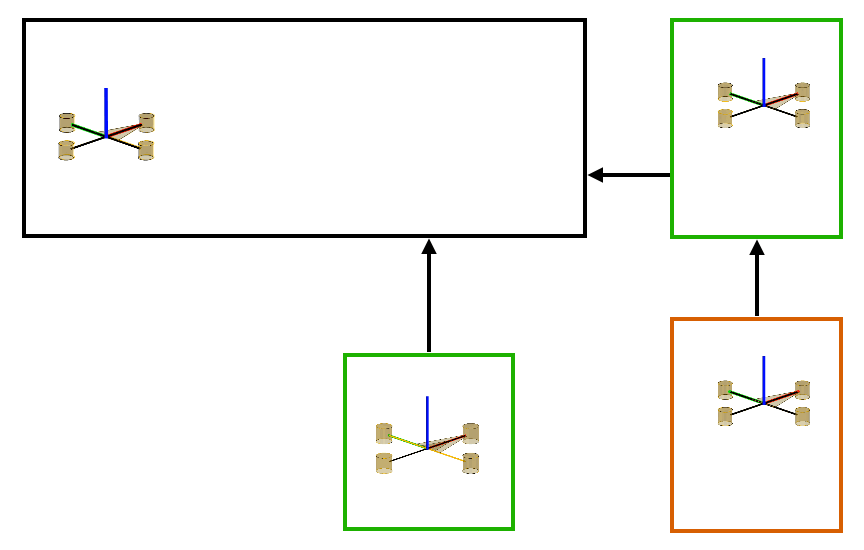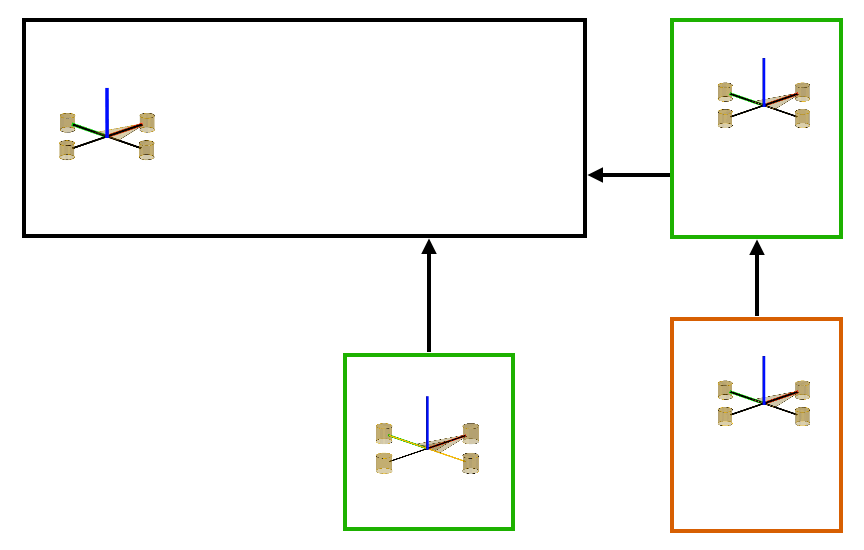
Figure 2: (a) Example of tree structure representing a hierarchy for a fictive system with four state variables and four control inputs is shown. Policies for inputs that lie in the same branch of the tree are computed starting from the leaf nodes moving up to the root. In this example, policies for u2 and u3 are jointly optimized by solving the optimal control problem for subsystem 1. Then a policy for u4 is computed. Finally, a policy for input u1 is obtained by solving the optimal control problem for subsystem 3. The resulting policies for different inputs are a function of different state variables. (b) A similar hierarchy for a quadcopter system.
Highly desireable hierarchies are those that offer substantial reduction in required computation for policy optimization while sacrificing minimally in closed-loop performance. Policy Decomposition combines these two competing criterias into a scalar fitness function shown below. F(δ) takes values between [0,1] where lower values indicate a more promising hierarchy. Here, Ferr(δ) simply scales the suboptimality metric introduced earlier to a value between [0,1] and Fcomp(δ) is an estimate of the number of floating point operations that would be required to compute the hierarchical policy vs the optimal policy.

In order to systematically search and find hierarchies that minimize the above fitness criteria, Policy Decomposition adapts two popular algorithms for combinatorial optimization, namely Genetic Algorithm and Monte-Carlo Tree Search, to search over the space of possible hierarchies. Illustrations of how these search methods operate are shown in Figure 3(a) and Figure 3(b) respectively. These search algorithms are suitably modified to make use of a bijective encoding scheme for hierarchies, a uniform sampling strategy to generate a population of hierarchies, and mutation operators that allow transformation between any two hierarchies for a system. For details, please refer [2].


Figure 3: (a) Genetic Algorithm adapted to search for hierarchies. A strategy to uniformly sample and mutation operators to iteratively modify a population of hierarchies is introduced. (b) Hierarchy search posed as a sequential decision making problem where Monte-Carlo Tree Search is used to construct a search tree over the space of hierarchies. The original undecomposed policy optimization problem forms the root node of the search tree and different hierarchies are constructed by iteratively decomposing.
Policy Decomposition constructs hierarchies for control based on a given choice of state variables and control inputs describing a system. However, this choice of system representation is critical. Consider the problem of obtaining an optimal controller for a quadcopter to hover in place. Hierarchies for the policy optimization of motor thrusts Fi that offer notable reduction in compute are highly suboptimal, and the hierarchy that minimizes the fitness criteria does not even produce stable closed-loop behavior. In contrast, more promising hierarchies are discovered if one uses the linearly transformed inputs of net thrust T and the roll, pitch and yaw differential thrusts (Froll, Fpitch and Fyaw respectively).
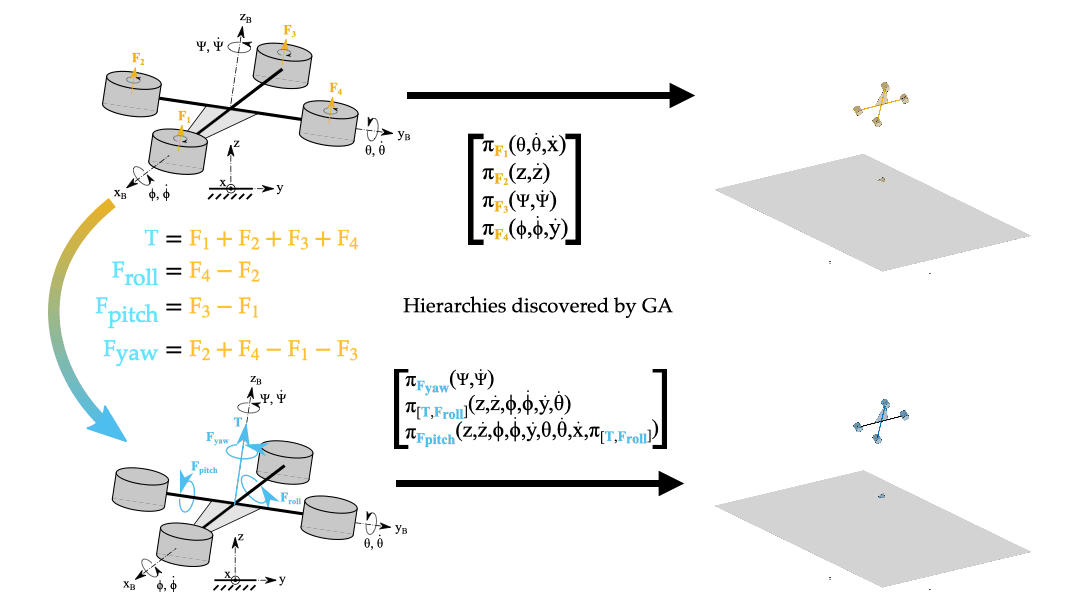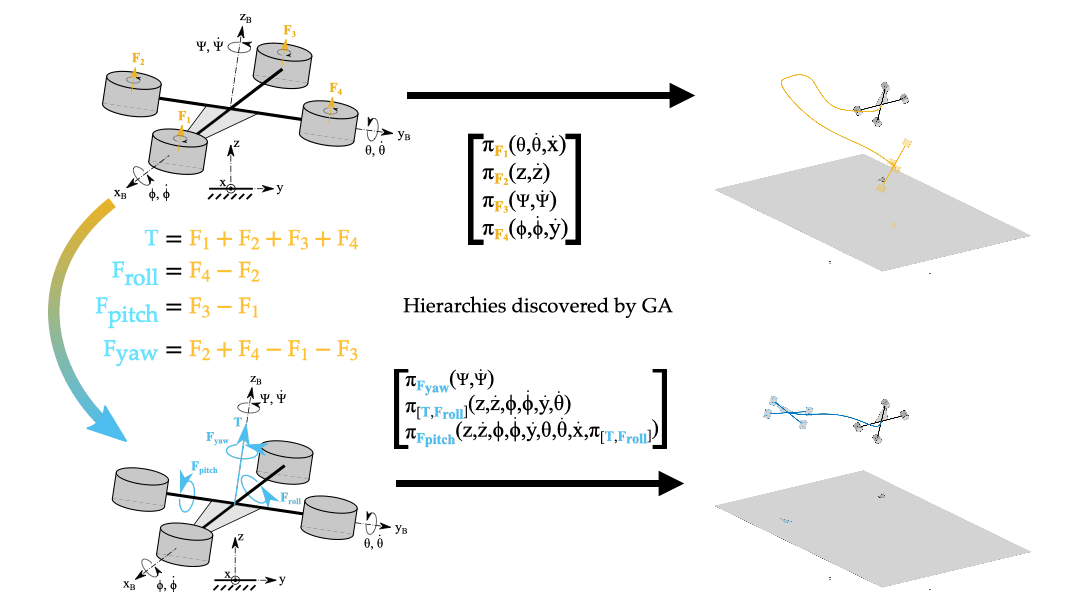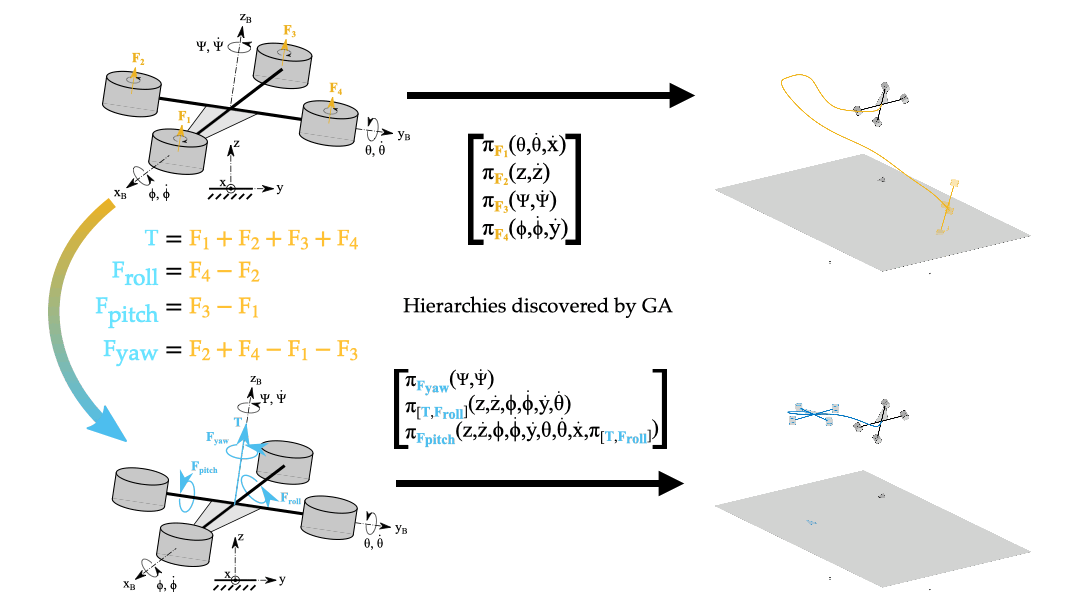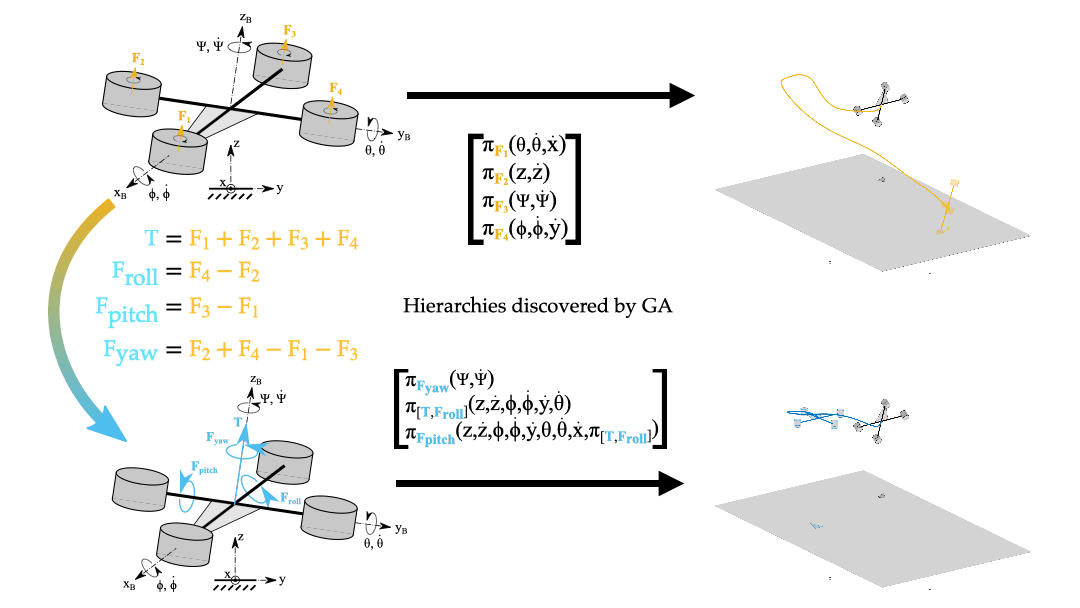
To further illustrate the idea, consider a linear system with two variables x1 and x2 shown in Figure 5. Any hierarchy imposed on this system results in suboptimal policies whereas for the linearly transformed system the optimal policies can be readily computed in a decoupled fashion. Note, that whether a system representation is amenable to hierarchical policy optimization is also dependent on the cost of the optimal control problem.
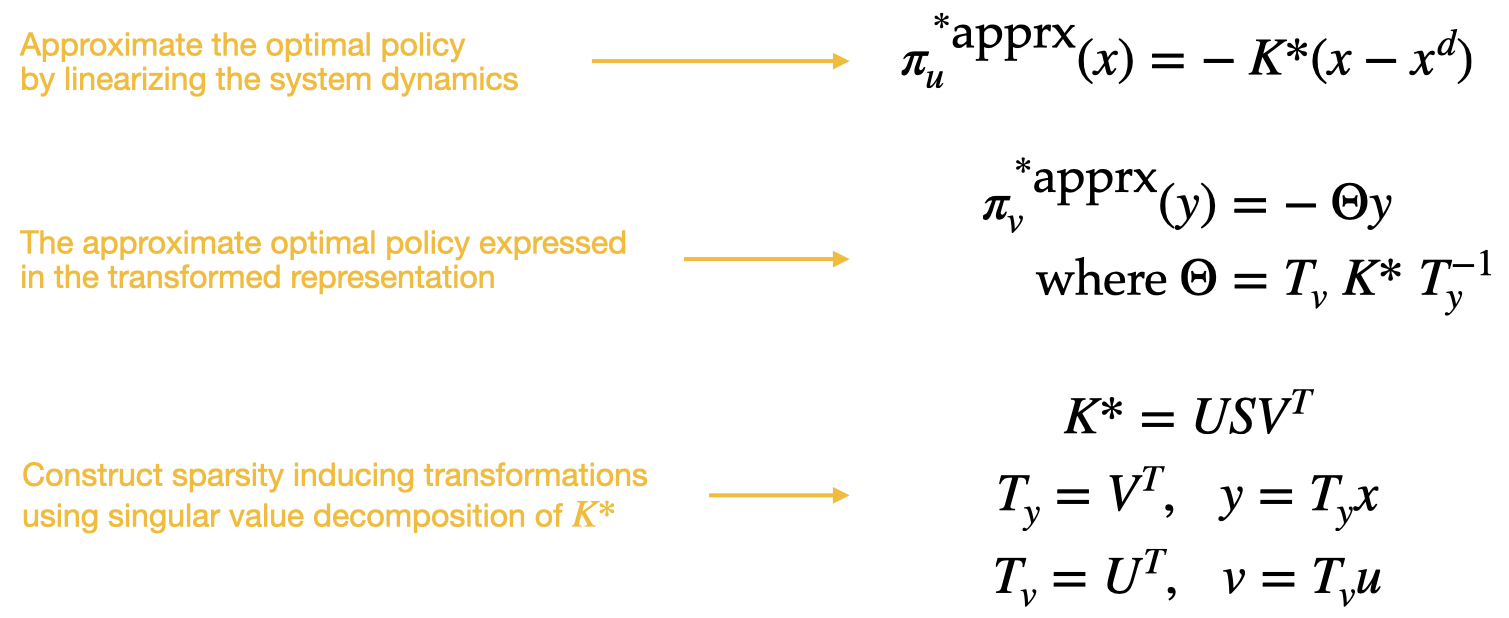
The Policy Decomposition framework also presents a heuristic approach to automatically derive system representations that lead to hierarchies with lower suboptimalities. It assumes a given representation for a system, i.e. state variables x and control inputs u, and constructs linear transformations (Ty, Tv) to system representations (y = Ty(x - xd), v = Tv(u - ud)) that lead to hierarchies with lower suboptimalities. Here, optimal regulation problems are considered where the objective is to drive the system to a fixed desired state xd and ud is the control input that stabilizes the system at this state. The approach to derive linear transformations Ty and Tv is based on the observation that any hierarchy enforces sparsity in the resulting policies at the cost of optimality, as policies for different inputs are restricted to be a function of only some subset of the state variables. Therefore, a system representation that already leads to a sparse optimal policy is more likely to generate hierarchies with lower suboptimalities. Since the optimal policy is not known, an estimate of the optimal policy is derived using the linearized system dynamics and solving an LQR problem, and the singular value decomposition of the optimal LQR gain is used to derive Ty and Tv (Figure 6). The singular value decomposition is need not be unique, if the matrix is rectangular or has repeated singular values and a regularization strategy is introduced to resolve this non-uniqueness. For details, please refer [3].
- A. Khadke and H. Geyer, Policy Decomposition : Approximate Optimal Control with Suboptimality Estimates, IEEE Humanoids 2020
- A. Khadke and H. Geyer, Search Methods for Policy Decomposition, ArXiv 2022
- A. Khadke and H. Geyer, Sparsity Inducing System Representations for Policy Decompositions, IEEE CDC 2022