I am interested in developing optimal control and reinforcement learning methods for control of dynamic robots.
During my Ph.D., I developed Policy Decomposition, a tool to automate the discovery of heirarchies for control that sacrifice minimally on optimality while providing substantial gains in sample efficiency.
Some of the systems that I am interested in, include legged robots,
Hierarchies for control are often hand-designed intuitively with little regard to their effect on the resulting closed-loop behavior. In this work, we present two search techniques for automatically discovering promising hierarchies for control. We demonstrate results on a range of robotic systems of varying complexity.
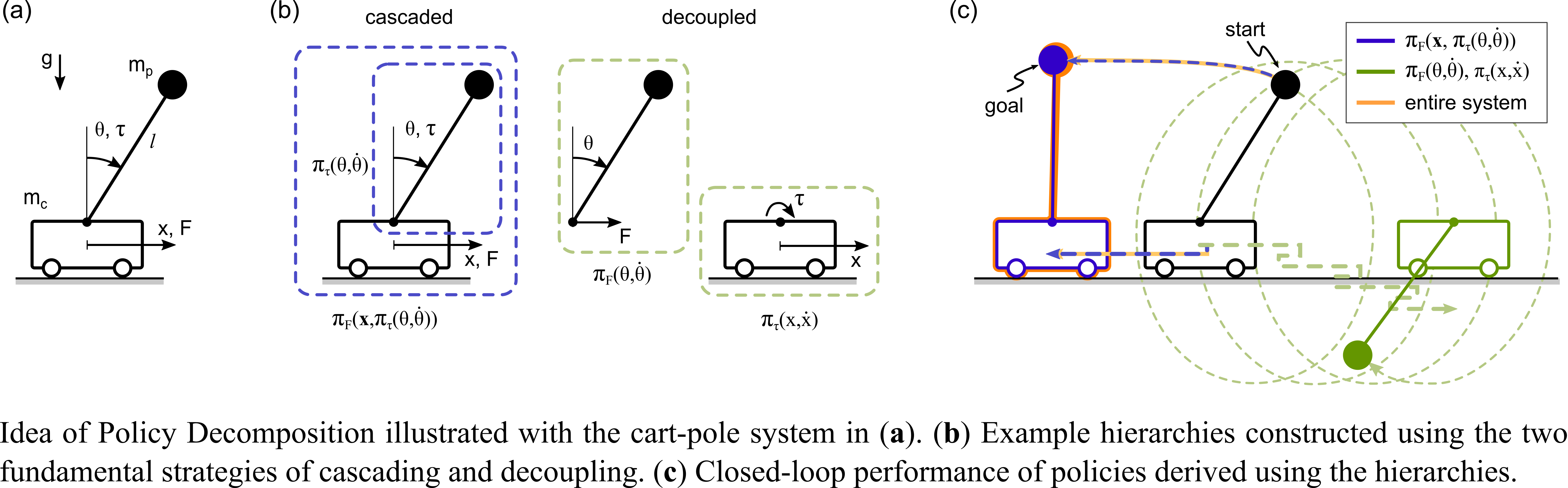
Policy decomposition is a novel framework for approximating optimal control policies of complex dynamical systems. The framework belongs to the class of hierarchical control methods which compose a control policy from optimal control solutions of smaller but tractable sub-systems. What stands out about policy decomposition is that it can estimate a priori how well the closed-loop behavior of different control hierarchies will match the unknown optimal policy of the entire system. Policy decomposition can therefore discover tractable control policies that give up little in closed-loop performance. However, this advantage does not come for free, as even for systems with moderate numbers of states and inputs, their vast number of possible hierarchies makes it impossible to estimate the closed-loop performance for all hierarchies. Here we demonstrate that this combinatorial challenge does not thwart the utility of policy decomposition. We identify a tree-like representation of any control hierarchy that policy decomposition can produce and use it to adapt two combinatorial search methods, Genetic Algorithm and Monte Carlo Tree Search, to the search for promising control hierarchies. Applying the so adapted search methods to characteristic regulator problems in robotics, we find that the Genetic Algorithm in particular discovers promising hierarchies, which produce control policies that perform better than common heuristic policies and policies obtained with popu- lar neural network learning strategies. These results suggest the utility of the policy decomposition framework, and we conclude with directions of future research that would broaden the type of problems to which policy decomposition can be applied
The Policy Decomposition framework hierarchically constructs optimal control policies for a dynamical system whereby policies for different inputs are solved for in a decoupled or cascaded fashion and only as functions of subsets of the state variables. As a consequence the choice of state variables and control inputs used to describe a dynamical system has an effect on the quality of resulting policies. In this work, we present a method to automatically discover system representations that are more amenable to such hierarchical policy optimization.
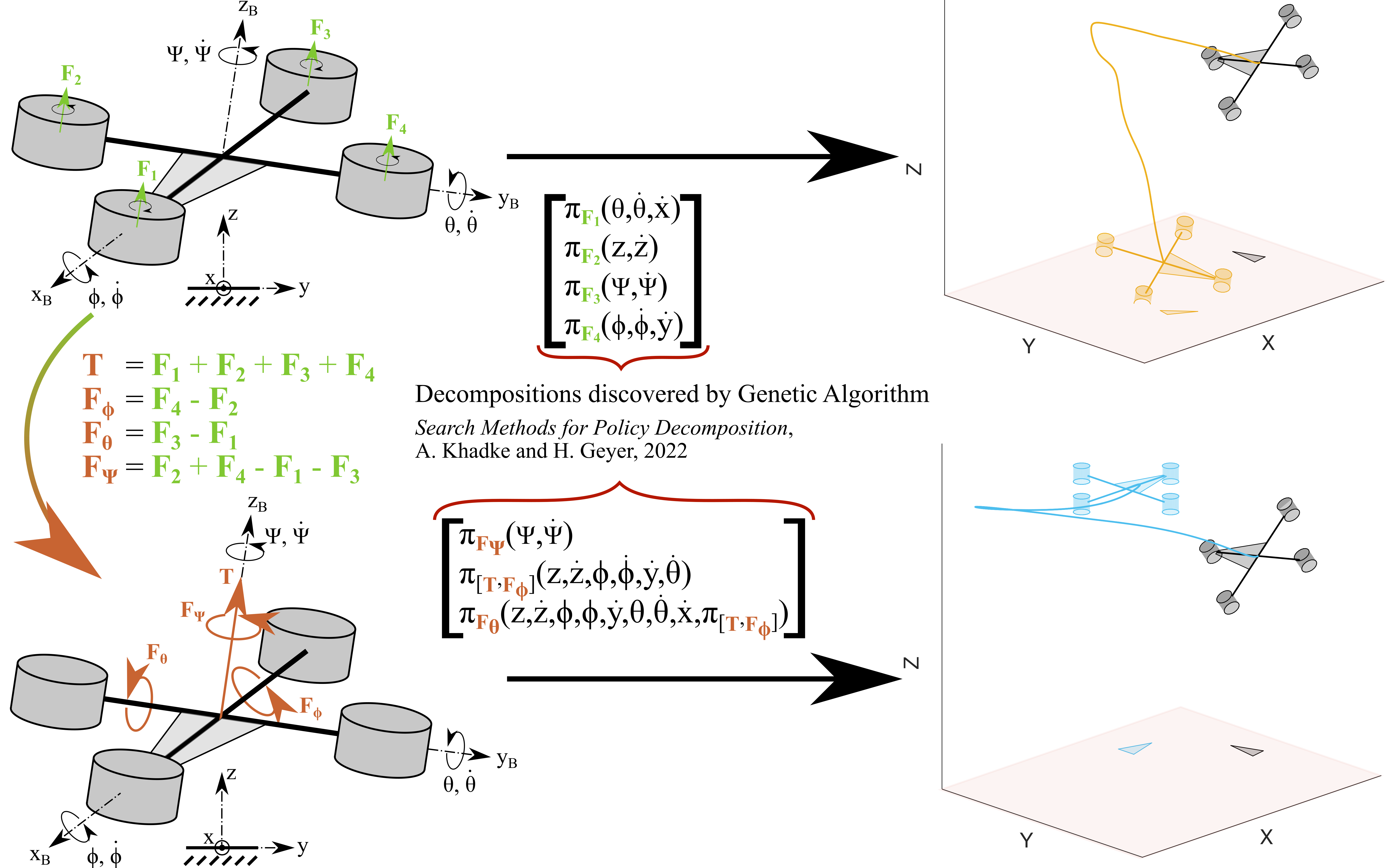
Policy Decomposition (PoDec) is a framework that lessens the curse of dimensionality when deriving policies to optimal control problems. For a given system representation, i.e. the state variables and control inputs describing a system, PoDec generates strategies to decompose the joint optimization of policies for all control inputs. Thereby, policies for different inputs are derived in a decoupled or cascaded fashion and as functions of some subsets of the state variables, leading to reduction in computation. However, the choice of system representation is crucial as it dictates the suboptimality of the resulting policies. We present a heuristic method to find a representation more amenable to decomposition. Our approach is based on the observation that every decomposition enforces a sparsity pattern in the resulting policies at the cost of optimality and a representation that already leads to a sparse optimal policy is likely to produce decompositions with lower suboptimalities. As the optimal policy is not known we construct a system representation that sparsifies its LQR approximation. For a simplified biped, a 4 degree-of-freedom manipulator, and a quadcopter, we discover decompositions that offer 10% reduction in trajectory costs over those identified by vanilla PoDec. Moreover, the decomposition policies produce trajectories with substantially lower costs compared to policies obtained from state-of-the-art reinforcement learning algorithms.
We tackle the curse of dimensionality in synthesizing global optimal control policies by reducing the original problem into a hierarchy of lower-dimensional subproblems. Hierarchies which offer dramatic reduction in computation while sacrificing minimally on closed-loop performance are readily identified using the suboptimality metrics we introduce.
Numerically computing global policies to optimal control problems for complex dynamical systems is mostly intractable. In consequence, a number of approximation methods have been developed. However, none of the current methods can quantify by how much the resulting control underperforms the elusive optimal solution. Here we propose policy decomposition, an approximation method with explicit suboptimality estimates. Our method decomposes the optimal control problem into lower-dimensional subproblems, whose optimal solutions are recombined to build a control policy for the entire system. Many such combinations exist, and we introduce the value error and its LQR and DDP estimates to predict the suboptimality of possible combinations and prioritize the ones that minimize it. Using a cart-pole, a 3-link balancing biped and N-link planar manipulators as example systems, we find that the estimates correctly identify the best combinations, yielding control policies in a fraction of the time it takes to compute the optimal control without a notable sacrifice in closed-loop performance. While more research will be needed to find ways of dealing with the combinatorics of policy decomposition, the results suggest this method could be an effective alternative for approximating optimal control in intractable systems.
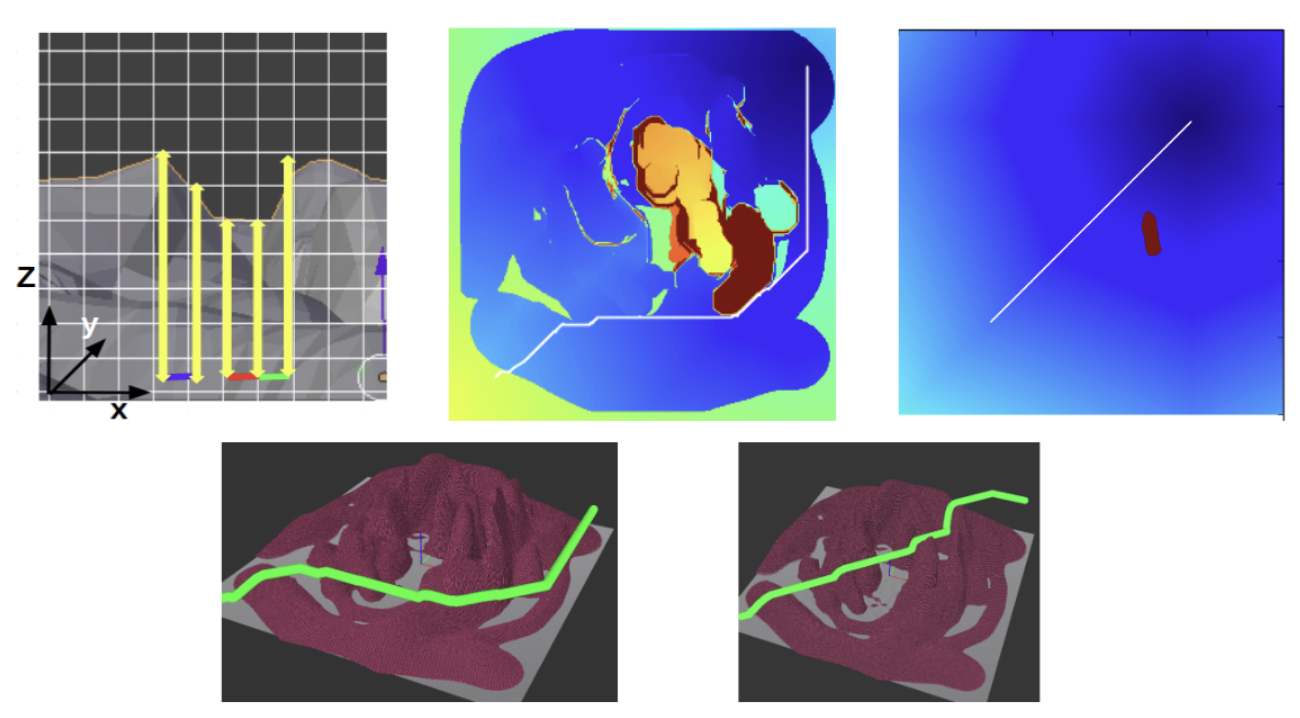
We present an algorithm to derive heuristics for graph-search based planning that explicitly minimize the search effort.
Weighted A* search (wA*) is a popular tool for robot motion-planning. Its efficiency however depends on the quality of heuristic function used. In fact, it has been shown that the correlation between the heuristic function and the true cost-to-goal significantly affects the efficiency of the search, when used with a large weight on the heuristics. Motivated by this observation, we investigate the problem of computing heuristics that explicitly aim to minimize the amount of search efforts in finding a feasible plan. The key observation we exploit is that while heuristics tries to guide the search along what looks like an optimal path towards the goal, there are other paths that are clearly sub-optimal yet are much easier to compute. For example, in motion planning domains like footstep-planning for humanoids, a heuristic that guides the search along a path away from obstacles is less likely to encounter local minima compared with the heuristics that guides the search along an optimal but close-to-obstacles path. We utilize this observation to define the concept of conservative heuristics and propose a simple algorithm for computing such a heuristic function. Experimental analysis on (1) humanoid footstep planning (simulation), (2) path planning for a UAV (simulation), and a real-world experiment in footstep-planning for a NAO robot shows the utility of the approach.
We present an active learning algorithm that discovers the suitability of a robotic system in performing different tasks. Drawing a prior from the robot's appearance, the algorithm levarages an information theoretic approach for experiment design to systematically build a model of the robot's capabilities.
As autonomous robots become increasingly multifunctional and adaptive, it becomes difficult to determine the extent of their capabilities, i.e. the tasks they can perform and their strengths and limitations at these tasks. A robot’s appearance can provide cues to its physical as well as cognitive capabilities. We present an algorithm that builds on these cues and learns models of a robot’s ability to perform different tasks through active experimentation. These models not only capture the robot’s inherent abilities but also incorporate the effect of relevant extrinsic factors on a robot’s performance. Our algorithm would find use as a tool for humans in determining ”What can this robot do?”. We applied our algorithm in modelling a NAO and a Pepper robot at two different tasks. We first illustrate the advantages of our active experimentation approach over building models through passive observations. Next, we show the utility of such models in identifying scenarios a robot is well suited for in performing a task. Finally, we demonstrate the use of such models in a collaborative human-robot task.
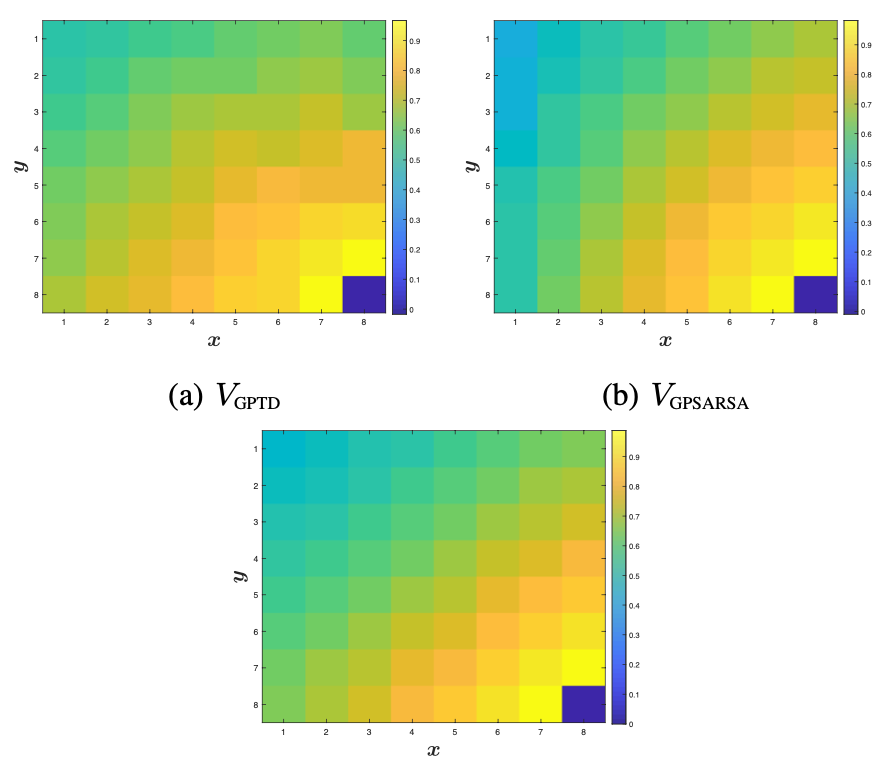
We investigate the use of Gaussian Processes as value function approximators and the utlity of the associated uncertainty estimate in improving exploration for policy learning.
In this work, we explore the use of Gaussian processes (GP) as function approximators for Reinforcement Learning (RL), and build estimates of the value function and Q-function using GPs. Such a representation allows us to learn Q-functions, and thereby policies, conditioned on uncertainty in the system dynamics, and can be useful in sample efficiently transferring policies learned in simulation to hardware.
We use two approaches, GPTD and GPSARSA, to build approximate value functions and Q-functions respectively. While for simple, continuous problems, we found these to be effective at approximating the value function and the Q-function, for discontinuous landscapes GPSARSA deteriorates in performance, even on simple problems. As the problem complexity increases, for example, for an inverted pendulum, we find that both approaches are extremely sensitive to the GP hyperparameters, and do not scale well. We experiment with a sparse variant of the algorithm but find that GPSARSA still converges to poor solutions. Our experiments show that while GPTD and GPSARSA are nice theoretical formulations, they are not suitable for complex domains without extensive hyperparameter tuning.
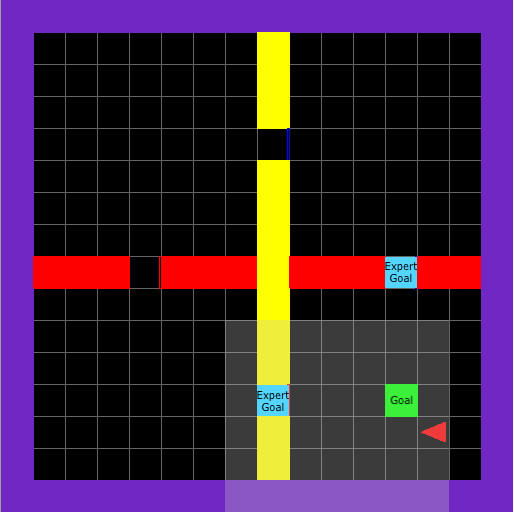
We present an algorithm to incorporate a set of expert policies to improve exploration and thereby the sample efficiency in policy optimization. Selection of suitable exploration actions is then posed as an 'online learning with expert advice' problem.
Exploration for Reinforcement Learning is a challenging problem. Random exploration is often highly inefficient and in sparse reward environments may completely fail. In this work, we developed a novel method which incorporates expert advice for exploration in sparse reward environments. In our formulation, the agent has access to a set of expert policies and learns to bias its exploration based on the experts’ suggested actions. By incorporating expert suggestions the agent is able to quickly learn a policy to reach rewarding states. Our method can mix and match experts’ advice during an episode to reach goal states. Moreover, our formulation does not restrict the agent to any policy set. This allows us to aim for a globally optimal solution. In our experiments, we show that using expert advice indeed leads to faster exploration in challenging grid-world environments.
Enabling robots to handle highly deformable objects for domestic purposes (cooking etc.) requires an accurate description of the object’s material properties. Additionally, being able to simulate the behavior of such objects in reasonable time is another requirement. Handling metallic or wooden objects is comparatively easy, as the rigid body assumption is quite accurate. This work investigates the Smoothed Particle Hydrodynamics method for simulating objects that undergo large deformations, such as rubber bands or pizza dough.
Enabling robots to handle highly deformable objects for domestic purposes (cooking etc.) requires an accurate description of the object’s material properties. Additionally, being able to simulate the behavior of such objects in reasonable time is another requirement. Handling metallic or wooden objects is comparatively easy, as the rigid body assumption is quite accurate. This work investigates the Smoothed Particle Hydrodynamics method for simulating objects that undergo large deformations, such as rubber bands or pizza dough.
Teaching
Graduate Student Instructor, Kinematics Dynamics and Control (16-711), Spring 2020
Graduate Student Instructor, Robot Kinematics and Dynamics (16-384), Fall 2018
Simulation of constrained dynamical systems (tutorial)